Analyser les contextes d’utilisation d’un mot avec AntConc
Ce scénario donne des exemples d’application et explique comment analyser quantitativement du contenu textuel avec le logiciel AntConc. Cet outil permet notamment d’analyser les contextes dans lesquels un mot est utilisé avec un algorithme d’analyse de cooccurrences.
Exemples d’application
Voici quelques exemples de projets réalisés avec l’aide de AntConc :
Analyse de procédés argumentatifs
Pour sa thèse de maîtrise, Serap Atasever Belli a utilisé AntConc afin d’analyser les procédés argumentatifs utilisés par les étudiants et étudiantes universitaires de Turquie et des États-Unis dans leurs travaux écrits. Elle ainsi pu comparer la fréquence d’utilisation des procédés par pays.
Apprentissage de la langue avec AntConc
Dans cet article, le créateur de AntConc, Laurence Anthony, montre comment l’application peut être employée pour enseigner une nouvelle langue, en replaçant des mots dans leurs contextes d’utilisation les plus fréquents. Il prend pour exemple l’apprentissage de l’anglais en contexte médical.
Objectifs du scénario
Dans ce scénario, nous allons analyser les contextes dans lesquels le mot « travail » est utilisé au sein des volumes 1 à 21 de la revue étudiante FéminÉtudes. Le but étant de savoir à quelles facettes de ce concept s’intéressent les personnes affiliées à l’Institut de recherche et d’études féministes de l’UQAM (IREF).
Bien sûr, vous pouvez appliquer les méthodes présentées dans ce scénario pour analyser autre chose que les intérêts d’une revue ou d’une organisation. Par exemple, vous pourriez identifier des tournures de phrases récurrentes chez un auteur ou une autrice, ou encore évaluer la réputation (positive ou négative) d’une personnalité publique à partir d’articles de presse qui la mentionnent.
Méthode
Comme il a été dit précédemment, nous allons analyser les contextes dans lesquels le mot choisi (dans notre exemple de scénario « travail ») est utilisé avec un algorithme d’analyse de cooccurrences. L’analyse de cooccurrences est une approche en analyse et fouille de texte qui consiste à repérer les mots qui en accompagnent souvent un autre dans un ensemble de textes.
L’analyse de cooccurrences permet de repérer des motifs qu’on ne remarquerait pas nécessairement en lisant un livre ou un groupe de plusieurs textes par soi-même.
Étapes du scénario

■ Préparer
Choisir les textes
La première étape consiste à choisir les textes que vous souhaitez analyser. Ces textes doivent être, autant que possible, représentatifs du phénomène qui vous intéresse. Plusieurs aspects sont à considérer :
- Format de fichier : les textes doivent tous être enregistrés au même format (CSV, TXT, PDF, etc.).
- Nombre : les textes doivent être assez nombreux pour être représentatifs de votre objet d’étude.
- Lien : il doit exister un lien clair entre les textes (même auteur ou autrice, même revue, même domaine de recherche, même sujet, etc.).
- Conditions d’utilisation : l’utilisation faite des textes doit respecter le droit d’auteur et les conditions d’utilisation des éditeurs.
Pour ce scénario, nous avons utilisé les volumes 11 et 15 à 21 de la revue FéminÉtudes. Ils ont été retrouvés sur le site de l’Institut de recherche et d’études féministes de l’UQAM.
Sauvegarder les textes sous un format de fichier valide
Avant de vous lancer dans l’exploration de AntConc, assurez-vous que les textes que vous souhaitez analyser sont sauvegardés sous un format de fichier accepté par le logiciel.
Les formats de fichier pris en charge par AntConc sont :
- Les plus recommandés : TXT, SRT, SUB.
- Autres formats : CSV, TSV, DOCX, PDF, HTML.
Si vous avez besoin de convertir vos textes sous un nouveau format de fichier et ne savez pas comment procéder, consultez cette page.
Pour ce scénario, nous avons utilisé des copies de FéminÉtudes qui ont été sauvegardées en format PDF, puis océrisées et converties en format TXT.
Nettoyer les textes
Assurez-vous aussi de nettoyer les textes de manière à supprimer toutes les informations impertinentes, par exemple le libellé des conditions d’utilisation. Ces informations viendront polluer l’analyse si elles ne sont pas préalablement supprimées.
Pour en savoir plus, voir Finding and Preparing Text.
Joindre les textes dans un dossier
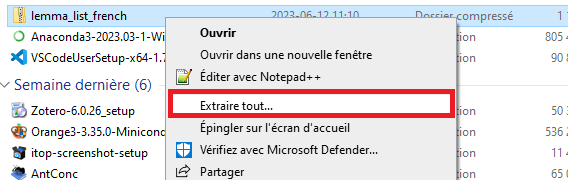
La dernière chose à faire avant d’ouvrir AntConc est de déplacer tous vos fichiers dans un même dossier. Ouvrez votre explorateur de fichiers. Sélectionnez tous vos textes avec CTRL+A, puis faites un clic droit. Dans le menu contextuel qui apparaît, sélectionnez « Envoyer vers », puis « Dossier compressé ».
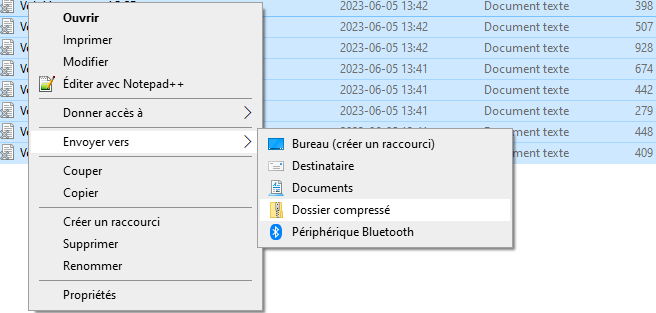
Donnez au dossier compressé nouvellement créé un nom qui facilitera son repérage. Puis, faites un clic droit sur le dossier compressé. Dans le menu contextuel qui apparaît, sélectionnez « Extraire tout ». Vous disposez maintenant d’un dossier que vous pourrez importer dans AntConc.
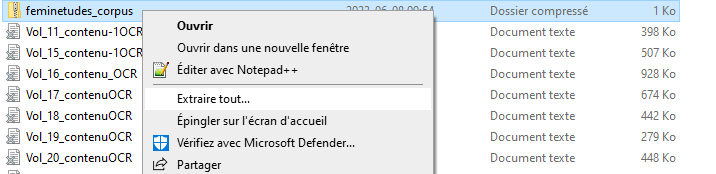
Pour ce scénario, nous avons regroupé les fichiers dans un dossier nommé « feminetudes_corpus ».
Importer les textes dans AntConc
Ouvrez AntConc. Cliquez sur « File », puis sur « Open corpus manager ».
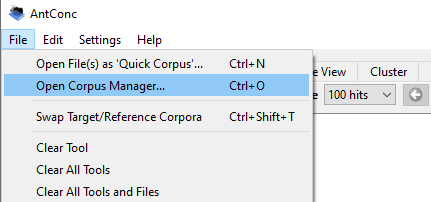
Dans la fenêtre contextuelle qui apparaît, cliquez sur « Raw File(s) », puis « Add Directory ». Votre explorateur de fichier s’ouvrira alors. Sélectionnez et chargez votre dossier, puis donnez un nom à votre corpus dans le Corpus Manager.
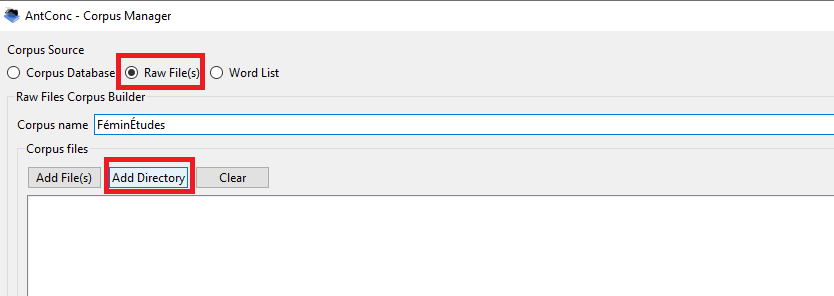
Prétraiter les textes
La prochaine étape consiste à prétraiter vos textes en ramenant chaque mot qui y figure à son lemme.
Téléchargez le fichier suivant. Dans votre explorateur de fichiers, faites un clic droit sur le fichier nouvellement téléchargé et sélectionnez « Extraire tout ». Vous aurez maintenant accès à un fichier en format TXT nommé « lefff-antconclex-f ». Il s’agit d’une liste de lemmes qu’AntConc utilisera pour lemmatiser automatiquement les mots dans votre corpus.
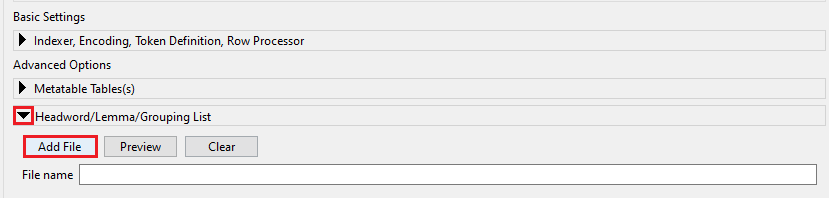
Retournez dans le Corpus Manager de AntConc. Déplacez votre curseur dans le coin inférieur gauche de la fenêtre et déroulez le menu « Headword/Lemma/Grouping ». Cliquez sur « Add file ». Votre explorateur de fichiers s’ouvrira alors. Chargez le fichier « lefff-antconclex-f » dans AntConc.
D’autres paramètres de prétraitement sont intégrés à AntConc, mais nous ne les utilisons pas dans le cadre de ce scénario.
Valider et créer son corpus
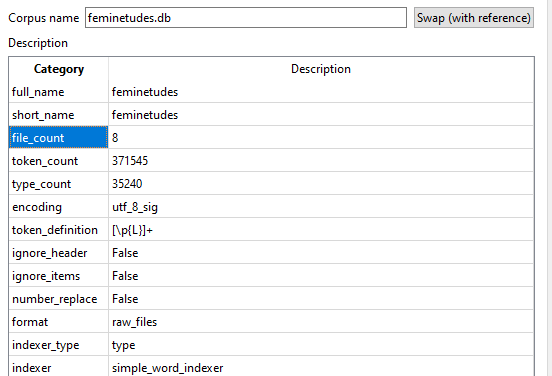
Cliquez sur le bouton « Create » en bas à gauche du Corpus Manager. Vous devriez alors voir apparaître, à droite de la fenêtre, un tableau avec des informations concernant le corpus nouvellement créé. Vérifiez si le nombre de fichiers TXT chargés dans AntConc est le bon à partir de la ligne « file_count ». Enfin, cliquez sur le bouton « Return to Main Windows » pour commencer l’analyse.
■ Rechercher et créer
Analyser les phrases autour d’un mot-clé
En haut de l’interface principale de AntConc se trouve une barre d’outils pour l’analyse de cooccurrences. Le premier des outils que nous allons utiliser est KWIC, pour « Key-word-in-context ». KWIC vous permet de voir les mots qui entourent chaque occurrence d’un mot-clé dans votre corpus. Il est ouvert par défaut lorsque vous commencez une analyse.
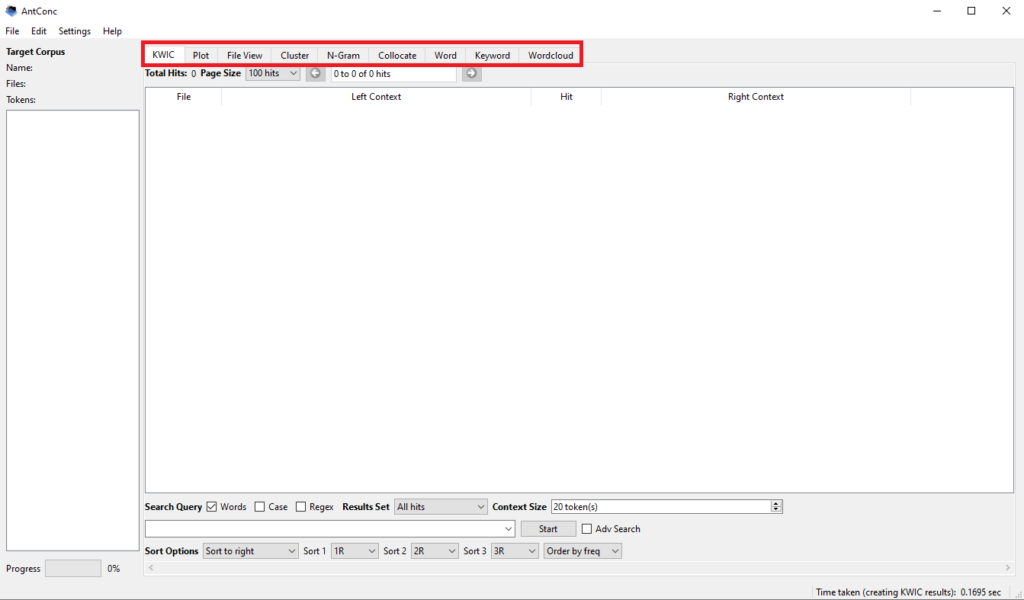
Glissez votre curseur en bas de la fenêtre. Dans la longue barre blanche qui est vide, entrez votre mot-clé. Puis, cliquez sur « Start » pour lancer l’analyse.

Vous verrez alors apparaître un tableau. Chaque ligne du tableau correspond à une occurrence de votre mot-clé à l’intérieur du corpus. Plus le mot-clé apparaît souvent dans votre corpus, plus le tableau comporte de lignes. Le nombre total d’occurrences du mot-clé est affiché en haut à gauche de la fenêtre.
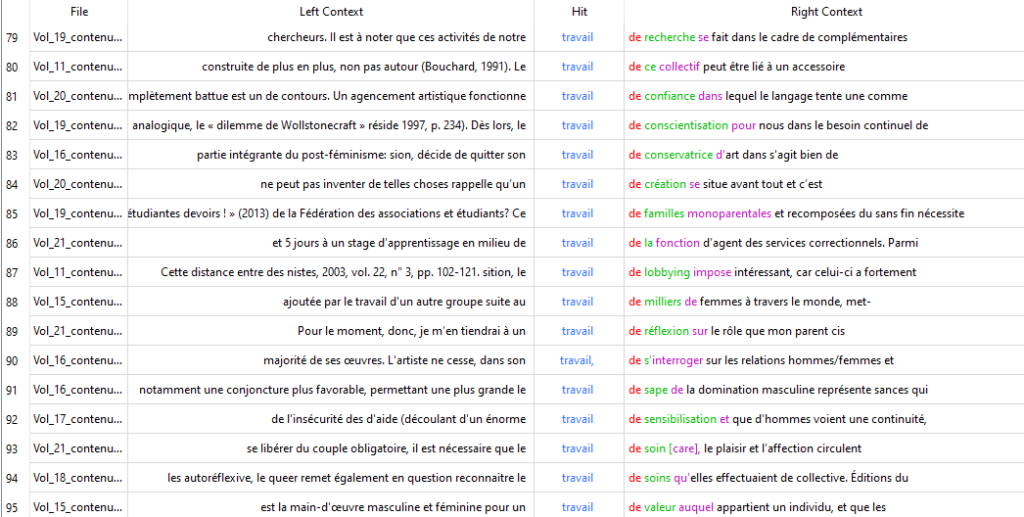
La première colonne du tableau indique le nom du fichier dans lequel se trouve l’occurrence du mot-clé. Les autres colonnes présentent les mots qui apparaissent avant le mot-clé (Left Context), le mot-clé en tant que tel (Hit), puis les mots qui apparaissent après le mot-clé (Right Context).
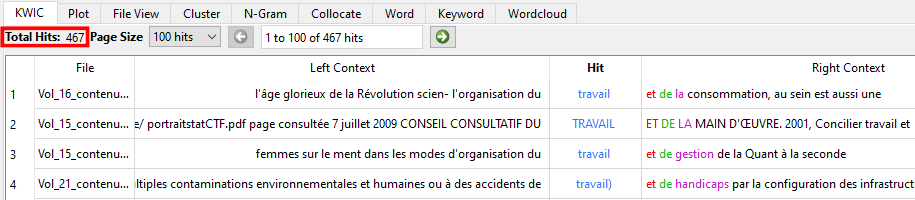
Observez votre tableau. Est-ce que votre mot-clé est souvent utilisé à l’intérieur de vos fichiers? Est-ce que vous remarquez des tendances, des tournures de phrase récurrentes dans les extraits à votre écran? Vous pouvez faire un double-clic sur une des occurrences pour lire le passage entier dans lequel elle se trouve avec l’outil « File View ».

Pour ce scénario, nous avons analysé le mot-clé « travail » avec KWIC. Ce mot apparaît 467 fois dans les numéros de FéminÉtudes choisis. On le retrouve souvent dans les expressions « organisation du travail » et « travail du sexe », ce qui indique que ces deux sujets sont importants pour les membres de l’IREF. En consultant certains passages avec « File View », on constate que le mot-clé n’as pas toujours un lien direct avec le sujet d’un article : par exemple, lorsqu’on analyse la formation au travail d’agent ou d’agente de services correctionnels pour émettre un constat sur le bien-être des femmes incarcérées.
Ajuster le nombre de mots entourant les occurrences
Vous pouvez augmenter ou réduire le nombre de mots qui entourent chaque occurrence de votre mot-clé en ajustant le paramètre « Context size ». Appuyez sur « Start » pour appliquer vos modifications.

Voir la répartition des occurrences par fichier
Le prochain outil que nous allons présenter se nomme Plot. Plot permet de visualiser la répartition des occurrences d’un mot-clé par fichier. Pour l’ouvrir, sélectionnez-le dans la barre d’outils, en haut de l’interface principale de AntConc.
Une fois l’outil ouvert, déplacez votre curseur en bas de la fenêtre. Entrez votre mot-clé dans la barre de recherche, puis cliquez sur « Start ». Vous verrez alors apparaître un tableau.
Chaque ligne du tableau désigne un fichier dans lequel votre mot-clé apparaît. La colonne « FileTokens » indique le nombre total de mots à l’intérieur du fichier, tandis que la colonne « Freq » donne le nombre d’occurrences du mot-clé à l’intérieur du fichier. La dernière colonne du tableau indique avec des barres de couleur bleue les passages du fichier où votre mot-clé est utilisé.
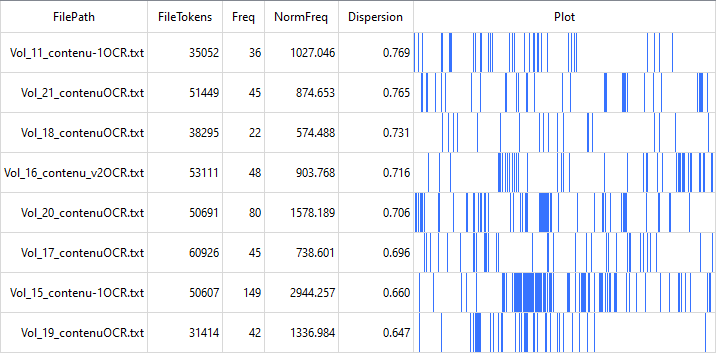
La mesure de dispersion permet de vérifier si l’usage du mot-clé est sporadique ou concentrée dans quelques passages. Plus elle est haute, plus les occurrences du mot-clé sont éparpillées dans le fichier.
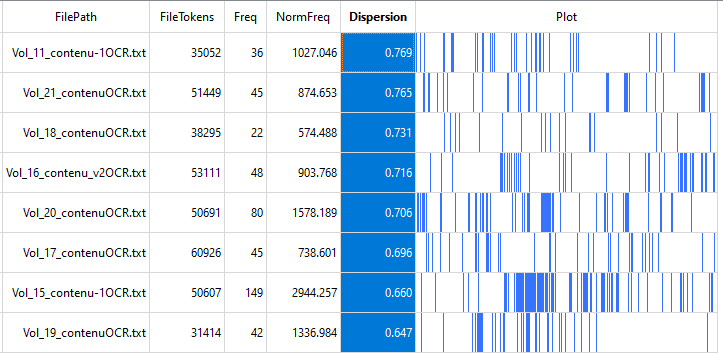
Observez votre tableau. Est-ce que votre mot-clé apparaît dans tous vos fichiers? Est-ce que son utilisation est concentrée dans certains passages clés? Vous pouvez faire un double-clic sur les barres de couleur pour lire les passages correspondants avec l’outil File View.
Pour ce scénario, nous avons analysé avec Plot la répartition du mot-clé « travail » dans les numéros de FéminÉtudes choisis. Le terme apparaît dans tous les documents, ce qui suggère encore une fois que le travail est un sujet important pour les membres de l’IREF qui contribuent à la revue. Les mesures de dispersion pour chaque fichier varient toutes entre 0,6 et 0,8, ce qui indique que le mot-clé est utilisé dans plusieurs sections de chaque numéro. On remarque qu’un grand nombre d’occurrences surviennent dans un passage du volume 15 en particulier. Une fois ouvert dans File View, ce passage s’est avéré correspondre à un article portant sur les revendications syndicales et féministes.
Comparer la distribution des occurrences pour deux mots-clés
Vous pouvez comparez la distribution des occurrences pour deux mots-clés en même temps. Retournez dans l’outil Plot, puis déplacez votre curseur en bas de la fenêtre. Tapez un premier mot-clé et appuyez sur « Start ». Puis, cochez l’option « Overlay » et cliquez sur le carré de couleur bleue pour lui assigner une nouvelle teinte. Entrez un nouveau mot-clé dans la barre de recherche et cliquez sur « Start ».

Dans le tableau nouvellement généré, la dernière colonne devrait présenter des barres de deux couleurs. Utiliser les paramètres d’agrandissement (Plot Zoom) pour mieux les observer. Est-ce qu’elles sont souvent rapprochées? Dans quels passages, quels fichiers? Faites un double-clic sur les passages qui vous semblent les plus intéressants pour les lire avec l’outil File View.
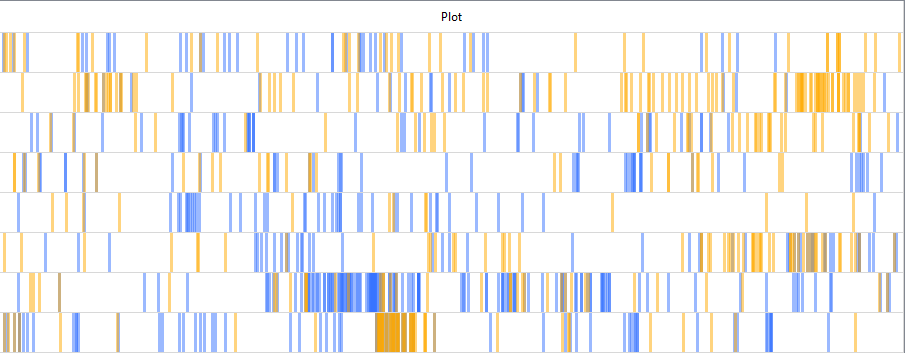
Pour ce scénario, nous avons analysé simultanément la répartition des mots-clés « travail » et « social » dans les numéros de FéminÉtudes choisis, afin de voir si le travail social était un sujet récurrent. La visualisation obtenue avec Plot nous a montré que, bien que ces mots-clés apparaissent ensemble à plusieurs reprises, il existe un grand nombre de passages qui mobilisent un seul d’entre eux.
Analyser les mots les plus fréquemment employés avec un mot-clé
Le dernier outil que nous allons utilisé dans le cadre de ce scénario s’appelle Collocate. Il permet de calculer quels sont les mots les plus susceptibles d’accompagner un mot-clé. Pour l’ouvrir, sélectionnez-le dans la barre d’outils, en haut de l’interface de AntConc.
Glissez votre curseur au bas de la fenêtre. Entrez votre mot-clé dans la barre de recherche en bas de la fenêtre, puis, cliquez sur « Start ». Vous verrez alors apparaître un tableau.
Chaque ligne du tableau désigne un mot qui apparaît souvent avec votre mot-clé. Par défaut, ils sont classés selon leur probabilité d’accompagner ou non votre mot-clé (likelihood). Les termes les plus hauts du tableau sont donc les plus susceptibles d’être utilisés avec votre mot-clé.
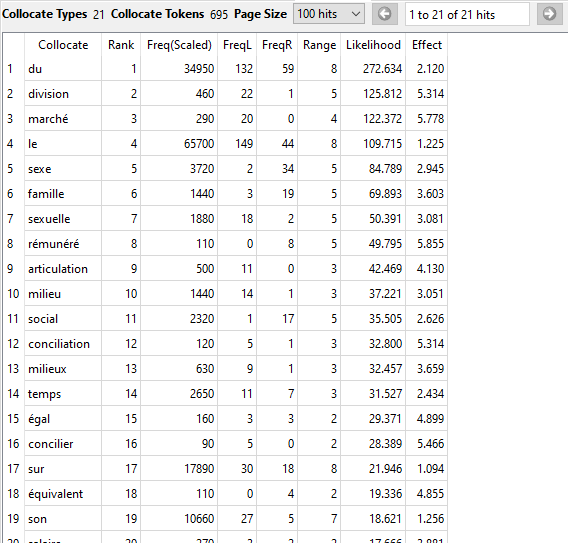
Observez votre tableau. Quels sont les mots les plus susceptibles d’être utilisés avec votre mot-clé? Est-ce que cela dit quelque chose à propos de la perspective des auteurs ou autrices de vos textes? Est-ce que vous pouvez discerner différentes facettes de votre mot-clé à partir des mots qui lui sont cooccurrents?
Pour ce scénario, nous avons utilisé Collocate pour dresser la liste des mots les plus susceptibles d’être utilisés avec le mot-clé « travail ». Les mots « division », « marché », « sexe » et « famille » figuraient parmi les premiers résultats. Nous en avons déduit que la division (sexuelle) du travail, les défis que rencontrent les femmes sur le marché du travail, le travail du sexe et la conciliation travail-famille chez les femmes sont autant d’enjeux importants pour les membres de l’IREF qui contribuent à FéminÉtudes.
Restreindre la portée de la recherche de cooccurrences
Vous pouvez restreindre la portée de la recherche en excluant les mots qui apparaissent à une distance x de votre mot-clé, soit avant (L) ou après (R) celui-ci. Pour ce faire, déplacez votre curseur en bas de la fenêtre, puis ajuster les valeurs de « L » et « R ». Si votre tableau contient beaucoup de déterminants (le, du, une, etc.) nous vous recommandons d’exclure les mots qui sont utilisés avant votre mot-clé en définissant la valeur de « L » à 0.

■ Diffuser
Créer et sauvegarder un nuage de mots
AntConc vous permet de créer un nuage de mots à partir des résultats de vos analyses. Pour ce faire, sélectionnez Wordcloud dans la barre d’outils. Déplacez votre curseur en bas à gauche de l’interface et cliquez sur le bouton à droite de « Source » afin de préciser l’analyse dont vous souhaitez représenter les résultats par une image. Une fois votre choix fait, cliquez sur « Start » pour générer un nuage de mots.

Vous pouvez changer la couleur et la police d’écriture des mots dans le nuage en modifiant les paramètres au bas de l’interface. Vous pouvez également ajuster la taille du nuage et limiter le nombre de mots à y inclure. Cliquez sur « Start » pour appliquer chacune de vos modifications.
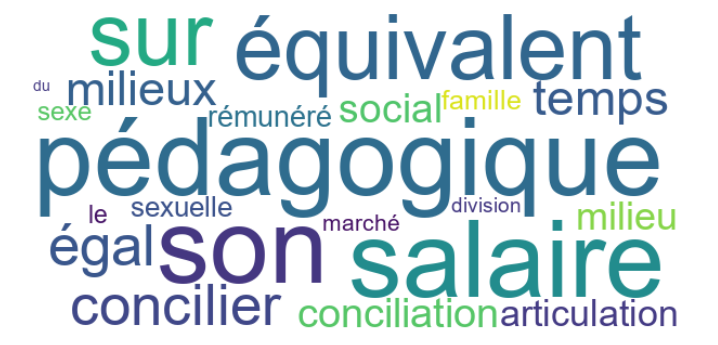
Une fois que vous avez obtenu un nuage de mots qui vous satisfait, déplacez votre curseur en haut à gauche de la fenêtre. Cliquez sur « File », puis sur « Save current tab results ». Votre explorateur de fichiers s’ouvrira alors. Nommer votre nuage de mots et sauvegardez-le sur votre ordinateur.