Mesurer la cohérence des partis politiques avec Orange Data Mining
Ce scénario donne des exemples d’application et explique comment analyser quantitativement du contenu textuel avec le logiciel Orange Date Mining. Cet outil permet notamment de mesurer la cohérence d’une organisation avec des algorithmes de classification automatique.
Si vous n’avez jamais utilisé ou ne connaissez pas Orange Data Mining, nous vous recommandons de consulter cette introduction avant d’aller plus loin. En outre, sachez que ce scénario utilise l’extension « Text ». Si vous ne l’avez pas encore installée, rendez-vous à la section « Télécharger des extensions » au bas de notre introduction au logiciel.
Exemples d’application
Les mots de la campagne
Le professeur Dominic Forest a utilisé des algorithmes de classification automatique pour mesurer la cohérence des partis politiques fédéraux à partir de leurs communiqués officiels. Il a ainsi pu identifier les partis courtisant le même électorat.
Filtrage de fausses nouvelles automatisé
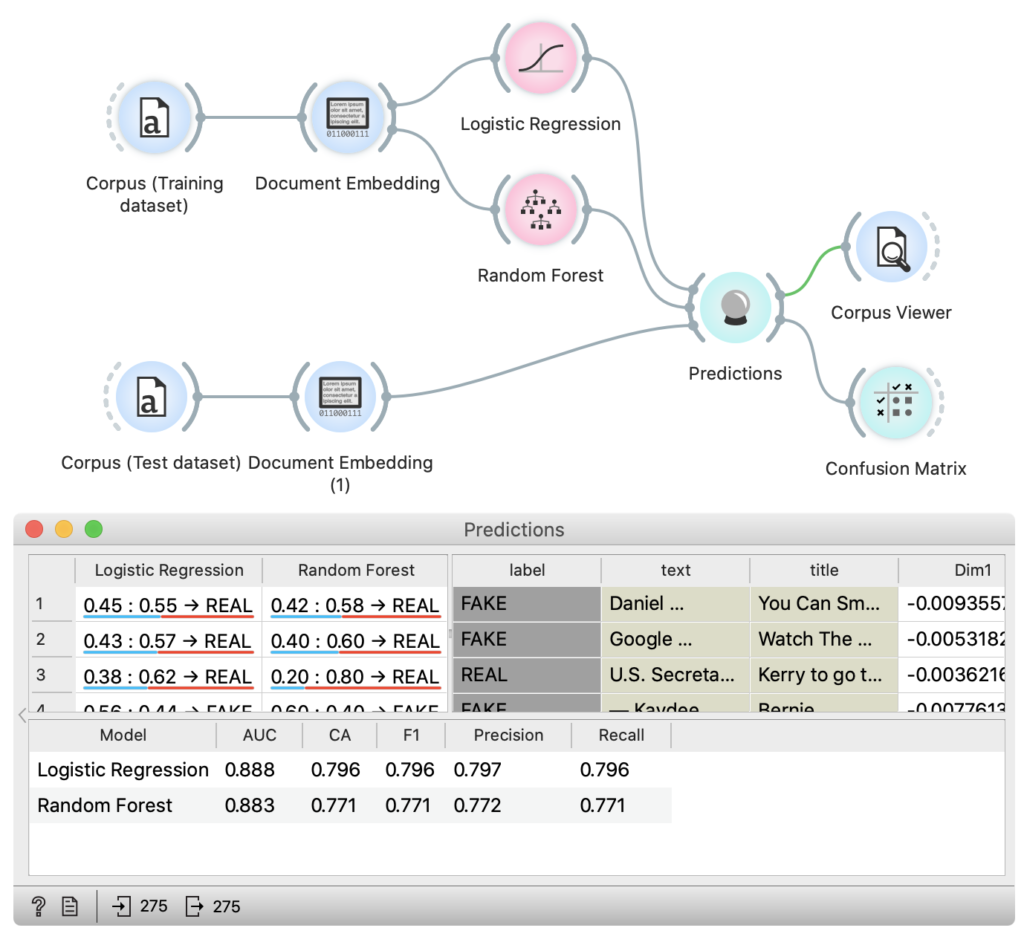
Primož Godec et Nikola Đukić ont utilisé Orange Data Mining pour entraîner un algorithme de classification automatique à trier des nouvelles selon qu’elles sont vraies ou fausses.
Objectifs du scénario
Dans ce scénario, nous allons mesurer la cohérence de deux partis politiques québécois, le Parti Libéral du Québec (PLQ) et le Parti Québécois (PQ), à partir des discours du budget prononcés par les ministres des finances de chacune de ces formations entre 1970 et 2018. Le but étant de savoir si ces formations politiques sont restées cohérentes au fil du temps, ou si elles ont au contraire emprunté des idées à leur adversaire au point de lui ressembler.
Évidemment, vous pouvez appliquer les méthodes présentées dans ce scénario pour analyser d’autres choses que des partis politiques : pourquoi ne pas mesurer la cohérence thématique de plusieurs auteurs ou autrices à l’intérieur d’un même genre, ou encore étudier l’inter-influence de revues dans un domaine de recherche donné?
Méthode
Comme il a été dit précédemment, nous allons mesurer la cohérence de nos catégories (le PLQ et le PQ) avec plusieurs algorithmes de classification automatique. La classification automatique est une approche en analyse et fouille de texte qui consiste à entraîner une intelligence artificielle à reconnaître la catégorie à laquelle un texte se rattache. Autrement dit, elle revient à apprendre à une intelligence artificielle à classer des textes par catégorie.
Les erreurs commises par un algorithme de classification automatique (c’est-à-dire les instances où l’intelligence artificielle attribue à un texte la mauvaise catégorie) peuvent nous en apprendre sur les interactions entre nos catégories. Par exemple, si deux partis politiques sont souvent confondus, c’est généralement signe qu’ils abordent les mêmes sujets, partagent des idées ou s’attaquent fréquemment.
Étapes du scénario

■ Préparer
Choisir les textes
La première étape consiste à choisir les textes que vous souhaitez analyser. Ces textes doivent être, autant que possible, représentatifs du phénomène qui vous intéresse. Plusieurs aspects sont à considérer :
- Format de fichier : les textes doivent tous être enregistrés au même format (CSV, TXT, PDF, etc.).
- Nombre : les textes doivent être assez nombreux pour être représentatifs de votre objet d’étude.
- Langue : les textes doivent être écrits dans la même langue.
- Lien : il doit exister un lien clair entre les textes (même auteur ou autrice, même revue, même domaine de recherche, etc.).
- Conditions d’utilisation : l’utilisation faite des textes doit respecter le droit d’auteur et les conditions d’utilisation des éditeurs.
Pour ce scénario, nous avons utilisé les discours du budget du Québec prononcés entre 1970 et 2018. Ils ont été retrouvés sur PolText, une base de données en science politique.
Sauvegarder les textes sous un format de fichier valide
Avant de vous lancer dans l’exploration de Orange Data Mining, assurez-vous que les textes que vous souhaitez analyser sont sauvegardés sous un format de fichier accepté par le logiciel.
Les formats de fichier pris en charge par Orange Data Mining sont :
- Les plus recommandés : TXT, DOCX
- Autres formats possibles : PDF, CSV, XML, ODT, CONLLU
Si vous avez besoin de convertir vos textes sous un nouveau format de fichier et ne savez pas comment procéder, consultez cette page.
Pour ce scénario, nous avons utilisé des copies des discours du budget qui ont été sauvegardées en format DOCX.
Nettoyer les textes
Assurez-vous aussi de nettoyer les textes de manière à supprimer toutes les informations impertinentes, par exemple le libellé des conditions d’utilisation. Ces informations viendront polluer l’analyse si elles ne sont pas préalablement supprimées.
Pour en savoir plus, voir Finding and Preparing Text.
Joindre les textes dans un dossier et les classer dans des sous-dossiers
La dernière chose à faire avant d’ouvrir Orange Data Mining est de déplacer tous vos fichiers dans un même dossier, puis de les ranger dans des sous-dossiers en fonction de leur catégorie. Ouvrez votre explorateur de fichiers. Sélectionnez tous vos textes avec CTRL+A, puis faites un clic droit. Dans le menu contextuel qui apparaît, sélectionnez « Envoyer vers », puis « Dossier compressé ».
Donnez au dossier compressé nouvellement créé un nom qui facilitera son repérage. Puis, faites un clic droit sur le dossier compressé. Dans le menu contextuel qui apparaît, sélectionnez « Extraire tout ». Vous disposez maintenant d’un dossier contenant l’intégralité de votre corpus.
Ensuite, identifiez les catégories que vous souhaitez analyser. Désirez-vous comparer des textes en fonction de leur auteur ou autrice, de leur sujet, de leur affiliation à un parti politique ou à une organisation, etc.? Cette étape est très importante, puisqu’elle influence les analyses que vous pourrez faire par la suite.
Une fois vos catégories identifiées, double-cliquez sur votre dossier pour y accéder, puis créez un sous-dossier pour chaque catégorie. Déplacez tous les textes appartenant à une même catégorie dans le sous-dossier correspondant. Enfin, nommez chaque sous-dossier d’après sa catégorie. Vous êtes maintenant prêt à importer votre corpus dans Orange Data Mining.
Pour ce scénario, nous avons créé un dossier nommé « Discours du budget ». Puis, des sous-dossiers pour les discours de chaque parti : « Parti libéral du Québec » et « Parti Québécois ».
Importer les textes dans Orange Data Mining
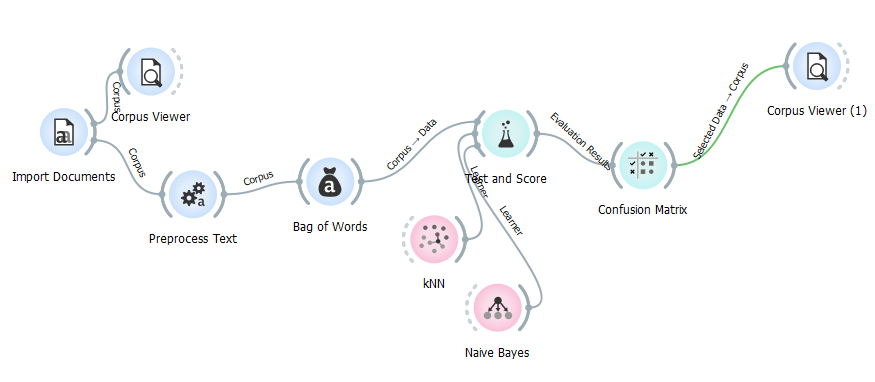
Ouvrez Orange Data Mining. Ajoutez un outil (widget) Import documents au tableau. Pour savoir comment fonctionne Orange Data Mining et comment utiliser des outils, consultez notre présentation du logiciel.

Double-cliquez sur l’outil Import documents. Dans la fenêtre contextuelle qui apparaît, cliquez sur l’icône de dossier pour accéder à votre explorateur de fichiers, puis chargez le dossier qui contient l’intégralité de votre corpus.
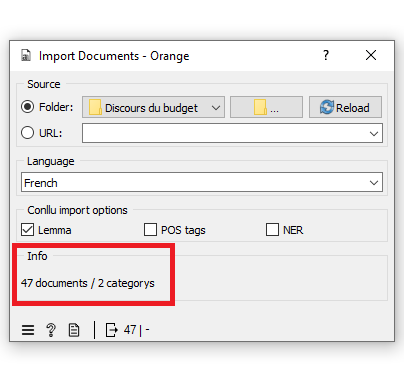
Une fois le chargement du dossier terminé, le nombre de documents et de catégories (sous-dossiers) devrait être indiqué au bas de la fenêtre contextuelle. Vérifiez si les informations indiquées sont correctes.
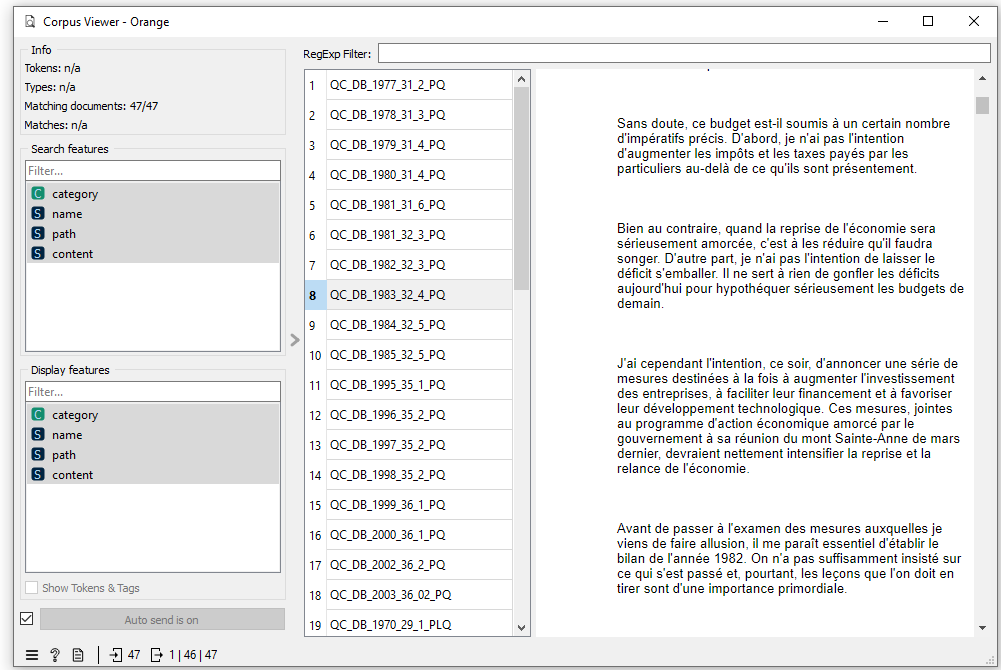
Vous pouvez visualiser votre corpus en ajoutant un outil Corpus Viewer au tableau, puis en le connectant après Import documents.
Double-cliquez sur Corpus Viewer pour ouvrir l’outil et consulter vos documents.
Prétraiter les textes
Vous devez maintenant prétraiter votre corpus afin de maximiser la précision des algorithmes qui seront utilisés plus tard. Ajoutez un outil Preprocess Text au tableau, puis connectez-le après Import documents.
Double-cliquez sur l’outil Preprocess Text, puis définissez les paramètres de prétraitement de vos textes. Cette étape aura un impact déterminant sur la qualité de vos résultats. N’hésitez pas à y revenir à plusieurs reprises pour améliorer vos résultats et peaufiner votre analyse.
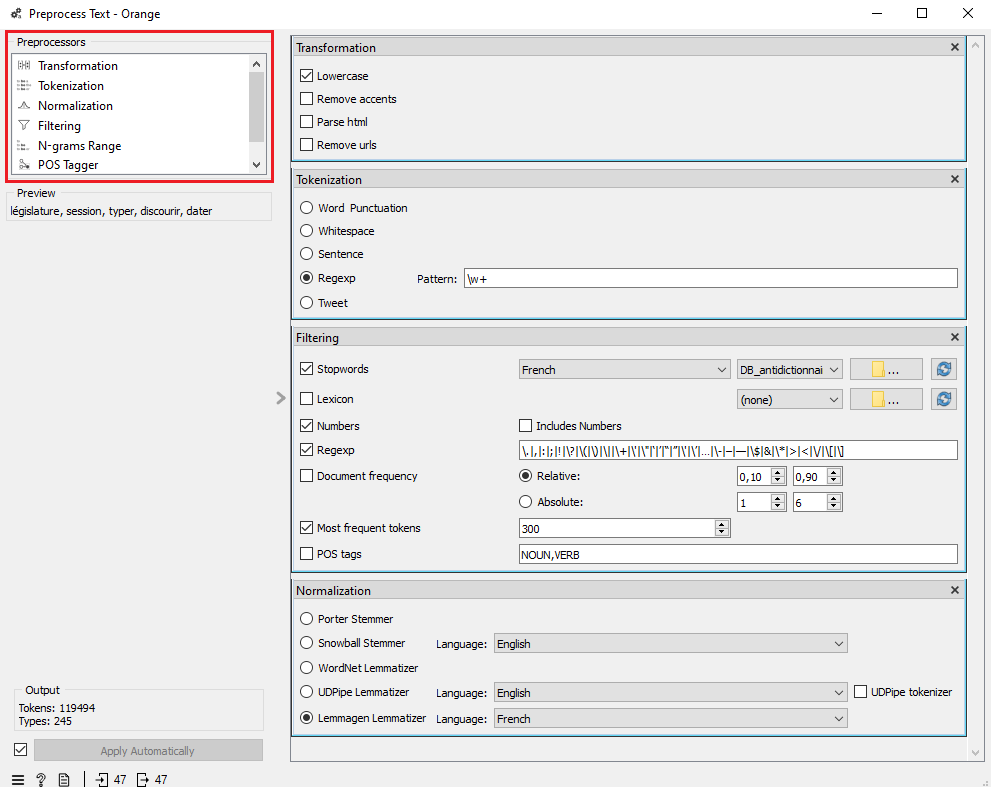
Les paramètres de prétraitement ont diverses fonctions :
- Les paramètres de transformation permettent de convertir tous les caractères en minuscules, ainsi que de retirer les accents, les balises html et les liens url de vos textes.
- Les paramètres de segmentation (tokenization) divisent chaque texte en de plus petites unités, par exemple des phrases ou des mots.
- Les paramètres de filtrage servent à retirer les mots vides, les signes de ponctuation, les nombres ou les termes présents dans trop peu ou trop de documents pour être significatifs. Ils permettent aussi de ne retenir que les mots les plus fréquents de votre corpus (most frequent tokens).
- Les paramètres de normalisation servent à ramener chaque mot soit à son lemme (lemmatisation) ou à sa racine (racinisation). Si vous travaillez avec des textes en français, nous vous recommandons d’utiliser le lemmatiseur Lemmagen.
D’autres paramètres de prétraitement sont offerts avec Preprocess Text, mais nous ne les utilisons pas dans le cadre de ce scénario. Pour en apprendre plus sur chaque paramètre, cliquez ici.
Pour ce scénario, nous avons transformé tous les caractères en minuscules, segmenté les textes par mot en excluant les signes de ponctuation (Regexp), filtré les mots vides en français et les nombres, et retenu les 300 termes les plus fréquents de notre corpus (voir Figure 10).
Créer et appliquer un antidictionnaire
Orange Data Mining vous permet de filtrer les mots vides de votre corpus, et même de créer un antidictionnaire adapté à votre sujet d’étude. Nous allons maintenant expliquer comment faire.
Orange Data Mining propose une liste de mots-vides en français. Pour l’appliquer à votre corpus, allez dans les paramètres de filtrage. Cliquez sur le bouton à droite de « Stopwords » et sélectionnez « French ». Seront alors exclus de votre analyse plusieurs mots-vides, par exemple les déterminants (le, la, une, etc.).
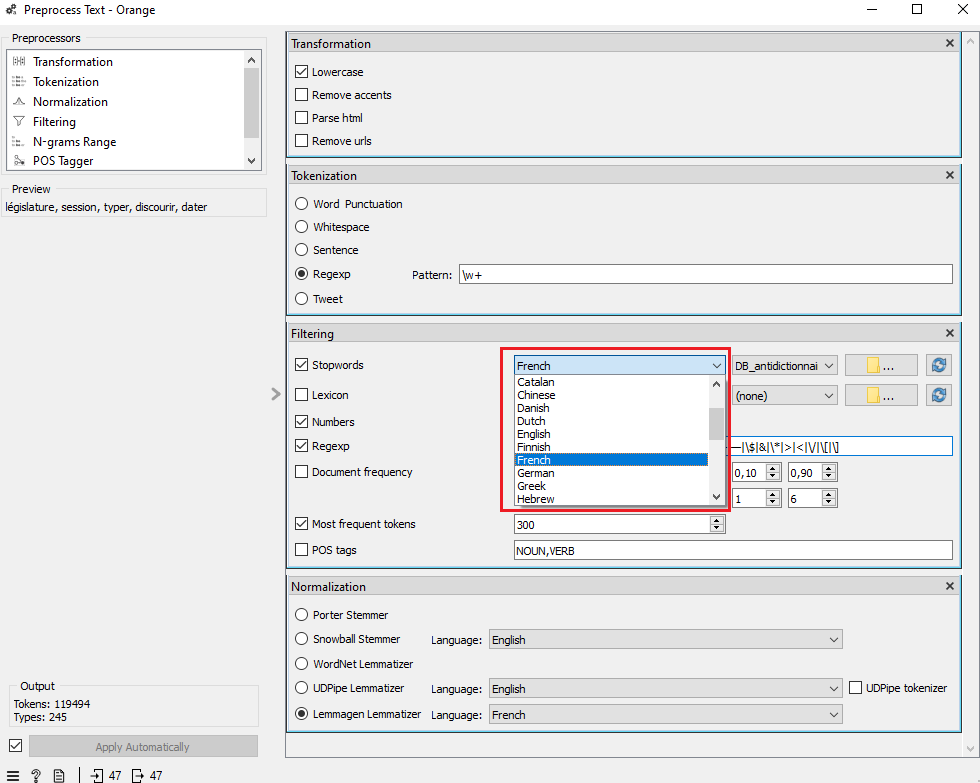
Cela dit, la liste de mots-vides fournie par Orange Data Mining n’est pas parfaite, et il peut valoir la peine de la compléter avec un antidictionnaire adapté à votre objet d’étude. Vous pourrez ainsi exclure des mots qui sont tellement fréquents dans votre corpus qu’ils n’ont aucune valeur discriminante (c’est-à-dire qu’ils ne sont caractéristiques d’aucune catégorie en particulier).
Sur votre ordinateur, ouvrez l’application Bloc-notes. Dans un nouveau fichier TXT, écrivez 1 mot que vous souhaitez exclure de votre analyse par ligne. Quand vous aurez terminé, sauvegardez votre fichier et fermez l’application Bloc-notes.
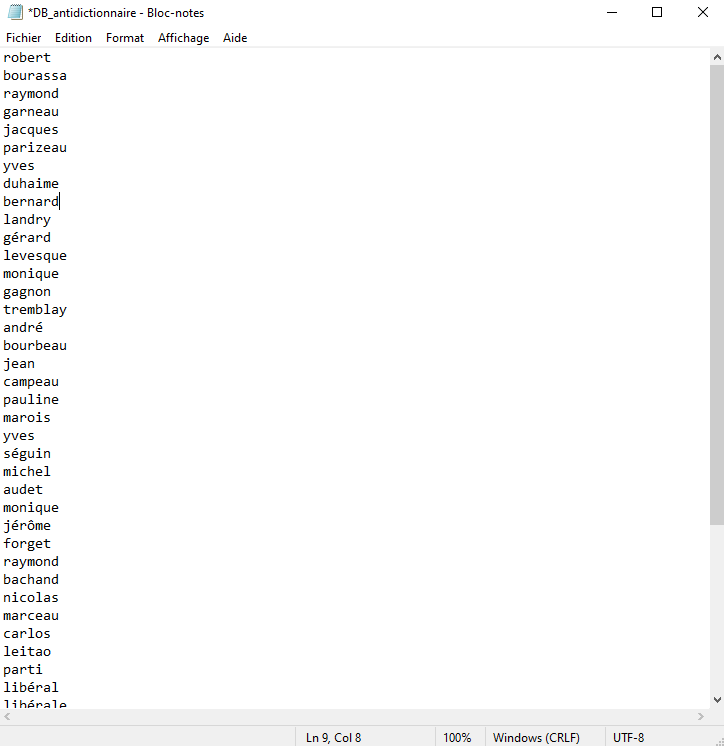
Retournez dans Orange Data Mining. Double-cliquez sur Preprocess Text. Dans les paramètres de filtrage, cliquez sur l’icône de dossier situé sur la même ligne que « Stopwords ». Votre explorateur de fichiers s’ouvrira alors. Sélectionnez et chargez votre antidictionnaire en fichier TXT. Les mots qu’il contient seront automatiquement exclus de l’analyse.
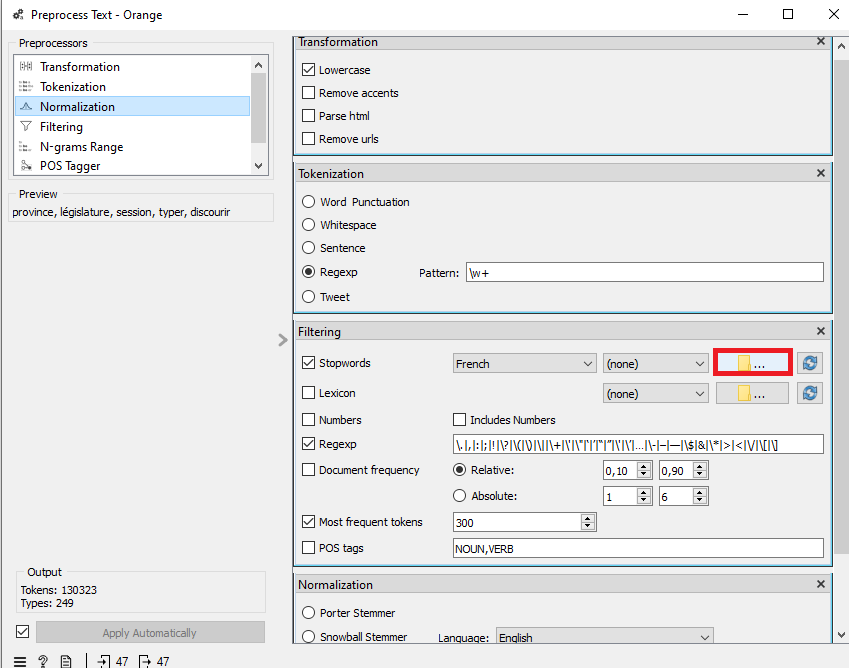
Pour ce scénario, nous avons créé un antidictionnaire avec les noms de tous les ministres des finances du Québec pour la période 1970-2018. Nous y avons aussi écrit les noms de nos catégories (« parti » « libéral », « québec ». « québécois ») de même que les mots qui s’y rapportent (« péquiste », « libéraux », etc.). Enfin, nous avons inclus dans notre antidictionnaire des mots comme « province », « président » et « budget », car ils sont présents dans tous les documents et ne sont donc pas discriminants.
Pondérer les textes
La prochaine étape consiste à transformer vos textes prétraités en valeurs numériques. Ajoutez un outil Bag of Words au tableau et connectez-le après Preprocess Text.
Dans le cadre de ce scénario, nous allons utiliser une pondération en TF-IDF. Double-cliquez sur Bag of Words, puis cliquez sur le bouton à droite de « Document Frequency » et sélectionnez « IDF ». Vous êtes maintenant prêt à appliquer des algorithmes de classification automatique sur votre corpus.
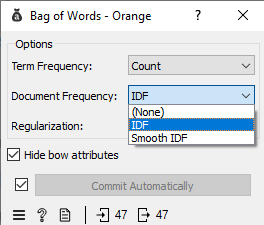
Pour en savoir plus sur le modèle « bag-of-words » en général, consultez la page suivante.
■ Rechercher et créer
Classification automatique
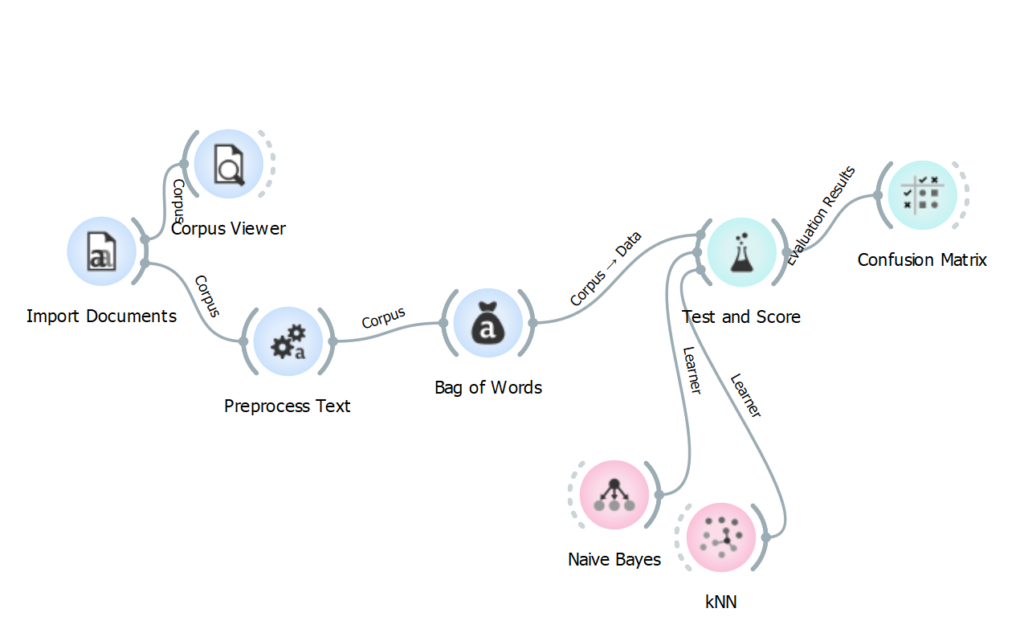
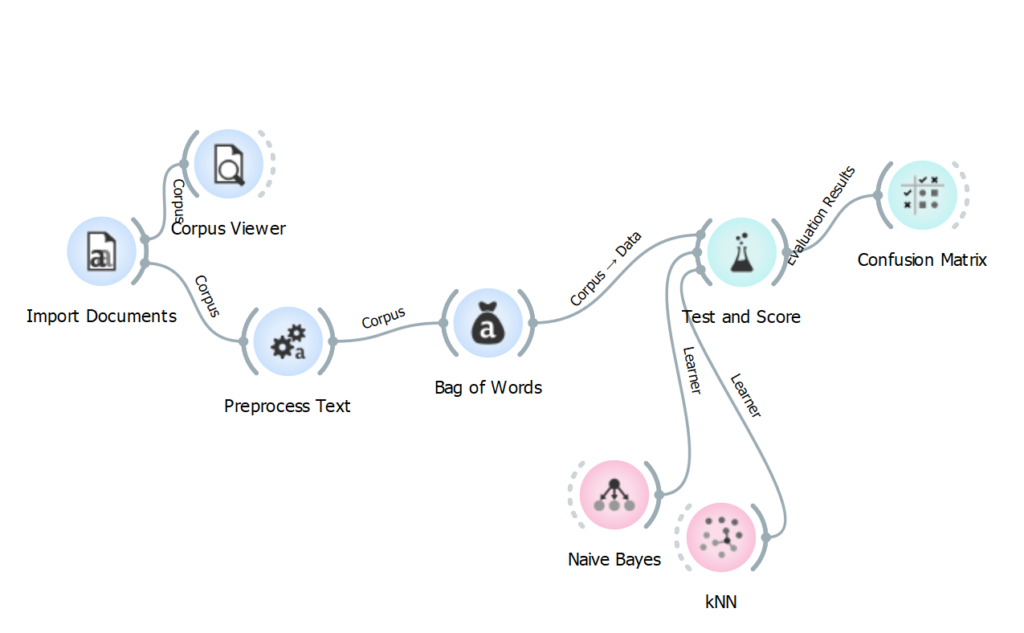
Ajoutez un outil Test and Score au tableau et connectez-le après Bag of Words. Puis, séparément de votre chaîne d’outils, ajoutez un outil Naive Bayes au tableau et connectez-le avant Test and Score. Faites la même chose avec un outil kNN. Test and Score devrait maintenant être connecté à trois outils.
Test and Score permet de mesurer les performances des algorithmes de classification automatique appliqués à votre corpus. Dans le cadre de ce scénario, nous utilisons deux algorithmes : la classification naïve bayésienne (Naive Bayes) et la méthode des k plus proches voisins (kNN). Sachez toutefois qu’Orange Data Mining en propose d’autres, qui s’appuient notamment sur les modèles de la régression logistique ou des forêts d’arbres décisionnels. Pour consultez la liste des algorithmes de classification automatique offerts avec le logiciel, consultez la section « Model » de son catalogue d’outils.
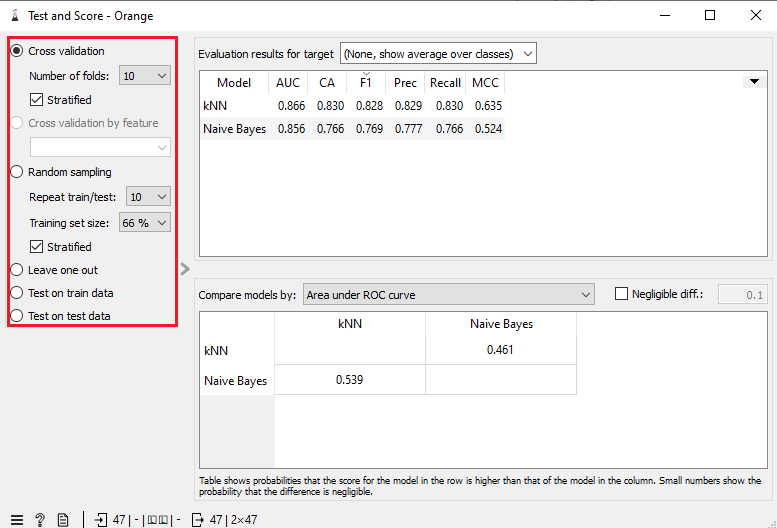
Nous allons maintenant évaluer la qualité des résultats obtenus avec Naive Bayes et kNN. Double-cliquez sur Test and Score. Au haut de la fenêtre contextuelle qui apparaît se trouve un tableau. Chaque ligne du tableau correspond aux résultats, en pourcentage (%), d’un algorithme en particulier. Normalement, votre tableau devrait comporter deux lignes : une pour Naive Bayes et une autre pour kNN.
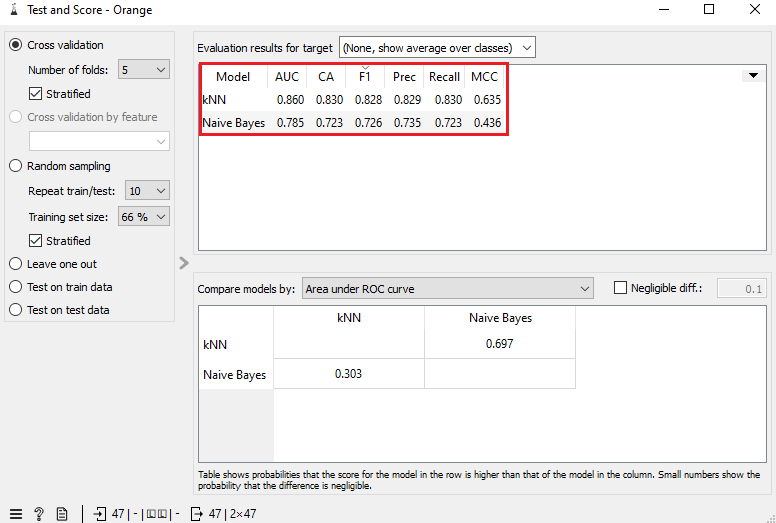
Les colonnes « Prec » et « Recall » du tableau des résultats indiquent respectivement les taux de précision et de rappel de votre analyse. La colonne « F1 » fournit quant à elle la moyenne des deux taux. Plus cette moyenne est haute, plus la classification faite par l’algorithme est bonne. En général, on considère qu’un score F1 supérieur à 0,8 est bon, et un score F1 supérieur à 0,9, excellent. Néanmoins, l’interprétation à donner à vos résultats dépend de votre corpus : lors du Défi Fouille de Textes 2016, l’équipe gagnante l’a emporté avec des scores F1 entre 0,2 et 0,3!
Des facteurs qui peuvent influencer négativement un score F1 sont :
- Le nombre de catégories : plus le nombre de catégories mobilisées est grand, plus il est difficile d’obtenir un bon score F1.
- Le nombre de textes : plus le nombre de textes qu’on soumet à un algorithme de classification automatique est petit, plus il est difficile d’obtenir un bon score F1.
- Ressemblances entre les catégories : plus les catégories mobilisées se ressemblent (et plus leurs ressemblances sont subtiles), plus il est difficile d’obtenir un bon score F1.
Observez les scores F1 que vous avez obtenus avec chaque algorithme. Sont-ils bons? Un algorithme a-t-il mieux performé qu’un autre? Comment expliquez-vous vos résultats?
Pour ce scénario, nous avons obtenu des scores F1 de 0,82 pour l’algorithme des k plus proches voisins et de 0,72 pour la classification naïve bayésienne. Nos deux algorithmes ont donc relativement bien performé, quoique la méthode des kNN ait été nettement plus efficace (+10%). Notre nombre restreint de catégories a certainement pu compenser pour la petite taille de notre corpus. À première vue, le PLQ et le PQ ont eu, entre 1970 et 2018, des politiques budgétaires plus distinctes que semblables.
Consulter les résultats par catégorie
Il est possible de consulter le score F1 pour une catégorie donnée. Dans Test and Score, cliquez sur le bouton « None, show average over classes » en haut de la fenêtre. Puis, sélectionnez une catégorie à la fois pour consulter les résultats qui y sont associés.
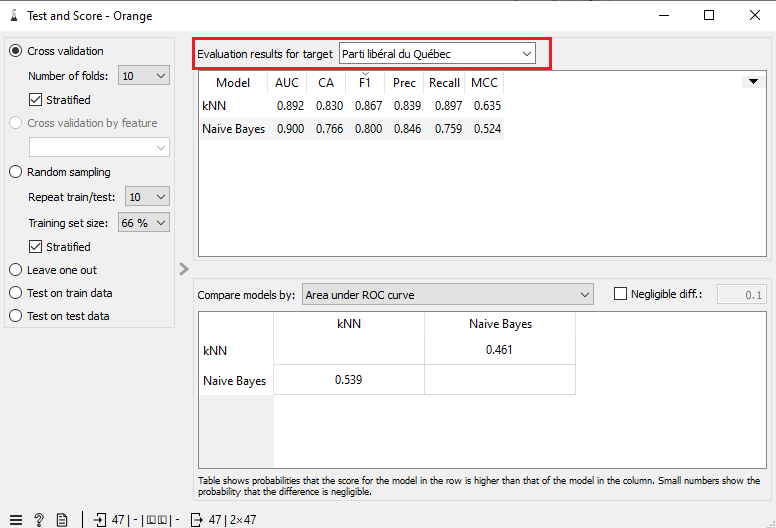
Comparez les scores F1 pour chaque catégorie. Une catégorie affiche-t-elle de meilleurs résultats que les autres? Quelle catégorie est la plus souvent confondue avec d’autres catégories?
Quand vous aurez fini, rétablissez l’affichage des résultats à « None, show average over classes ».
Pour ce scénario, nous avons obtenu des scores F1 de 0,86 et 0,76 pour le PLQ et de 0,76 et 0,66 pour le PQ. Manifestement, le PQ est un parti dont les politiques budgétaires ont été moins cohérentes que celles du PLQ.
Améliorer ses résultats
Nous allons maintenant tenter d’améliorer nos résultats. Toujours dans Test and Score, déplacez votre curseur dans la colonne à gauche de la fenêtre contextuelle. Cette section contient les paramètres d’échantillonnage de votre corpus :
- La validation croisée (cross-validation) sépare vos textes en blocs (folds), que l’algorithme exclura un à la fois en s’entraînant. Généralement, on peut améliorer la performance de cette méthode en ajustant le nombre de blocs. Pour ce faire, cliquez sur le bouton à droite de « Number of folds ».
- L’échantillonnage aléatoire (random sampling) entraîne l’algorithme à partir d’une proportion de votre corpus définie aléatoirement.
- la validation LOOCV (leave one out cross-validation) entraîne l’algorithme en excluant un texte du corpus à la fois. Elle est considérablement longue à exécuter lorsque votre corpus contient beaucoup de textes.
D’autres paramètres sont offerts avec Test and Score, mais nous ne les présentons pas dans le cadre ce scénario. Pour en apprendre plus sur les méthodes d’échantillonnage proposées par Orange Data Mining, consultez cette page.
Si vos résultats ne s’améliorent pas après avoir modifié les paramètres d’échantillonnage, ou s’ils restent décevants, retournez dans Preprocess Text et modifiez vos paramètres de prétraitement : ajoutez des termes dans votre antidictionnaire, modifiez le nombre de mots fréquents à retenir (most frequent tokens), etc. Essayez différentes combinaisons de paramètres et notez les résultats obtenus pour chacune d’elles, jusqu’à aboutir à des résultats définitifs. L’analyse et la fouille de texte implique souvent des essais-erreurs.
Pour ce scénario, nous avons obtenu nos meilleurs résultats avec une validation croisée à 10 blocs. Nous obtenons donc des scores F1 de 0,82 pour l’algorithme des k plus proches voisins et de 0,76 pour la classification naïve bayésienne.
Matrice de confusion
Analysons maintenant les erreurs commises par les algorithmes de classification automatique. Comme nous l’avons dit, ces erreurs pourront nous en apprendre sur les interactions entre nos catégories.
Ajoutez un outil Confusion Matrix au tableau et connectez-le après Test and Score.
Double-cliquez sur Confusion Matrix. Dans la fenêtre qui apparaît se trouve un tableau, communément appelé une matrice de confusion. Chaque ligne de la matrice de confusion correspond à la catégorie réelle d’un texte, et chaque colonne, à la catégorie prédite par l’algorithme de classification automatique. Vous pouvez ainsi consultez le nombre d’erreurs commises pour chaque catégorie. Cliquez sur « kNN » ou « Naive Bayes » dans la colonne à gauche de la fenêtre contextuelle pour voir les résultats obtenus par chaque algorithme.
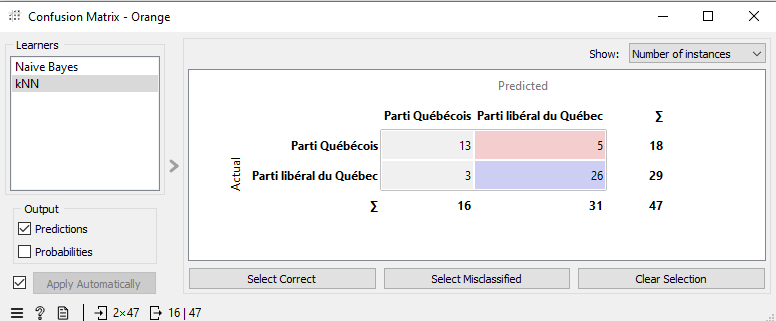
Observez vos matrices de confusion. Quelles catégories ont été les plus souvent confondues? Lesquelles ont été confondues même par votre algorithme le plus performant? Comment pouvez-vous l’expliquer?
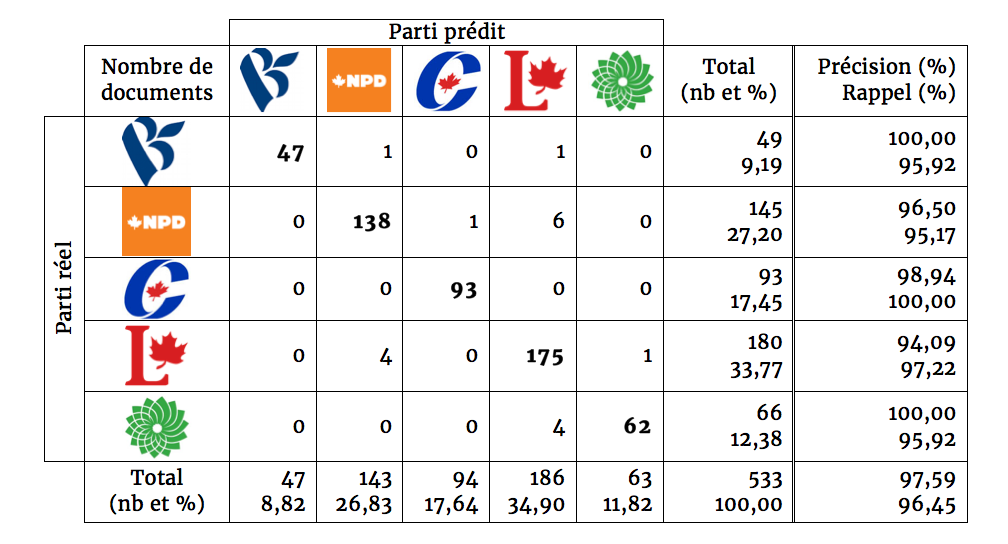
Pour ce scénario, nous avons généré une matrice de confusion à partir de nos meilleurs résultats. Avec la classification naïve bayésienne, on compte 13 erreurs : 8 textes du PLQ ont été attribués au PQ, et 5 textes du PQ, au PLQ. Avec la méthode des k plus proches voisins, on compte 8 erreurs : 3 textes du PLQ ont été attribués au PQ, tandis que 5 textes du PQ ont été rattachés au PLQ.
Analyser les erreurs
La dernière étape consiste à lire et à analyser les textes qui ont été mal classés par les algorithmes. En effet, la fouille et l’analyse textuelle ne peut pas se passer d’une part importante d’interprétation humaine! Il faut maintenant comprendre si les erreurs d’attribution commises par les algorithmes de classification automatique relèvent de véritables ressemblances entre vos catégories, ou si elles dépendent d’une autre dynamique.
Toujours dans la matrice de confusion, cliquez sur le bouton « Select Misclassified », puis fermez la fenêtre contextuelle.
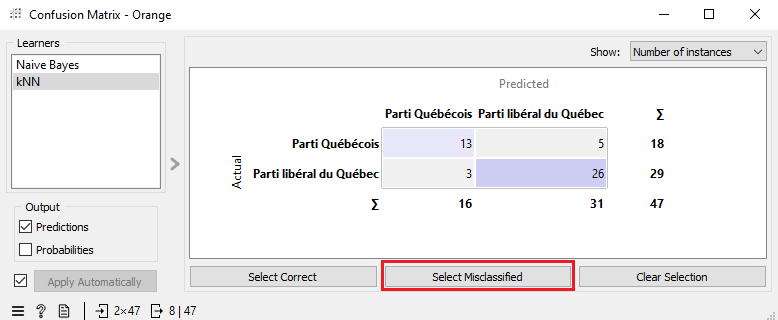
Ajoutez un outil Corpus Viewer au tableau, puis connectez-le après Confusion Matrix. Double-cliquez sur Corpus Viewer pour l’ouvrir.
En bas à gauche de la fenêtre contextuelle qui apparaît, sélectionnez tous les paramètres sous « Display features ». Vous pourrez ainsi voir, pour chaque texte, sa catégorie réelle, son contenu et sa catégorie prédite. Cette dernière se trouve tout au bas du texte.
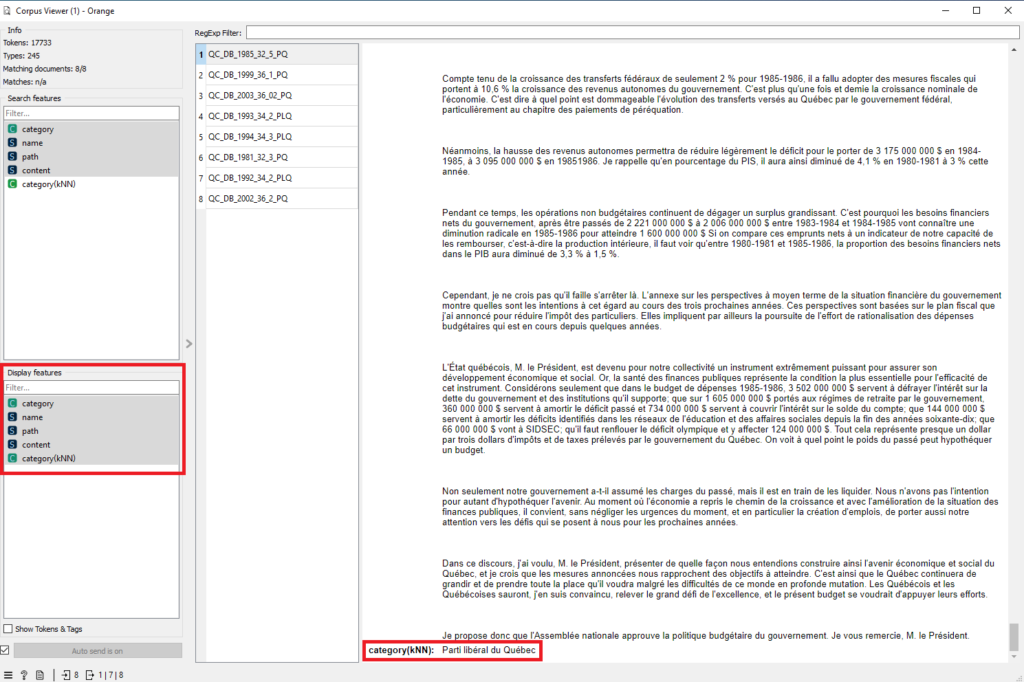
Lisez et analysez les textes qui ont été incorrectement classés. Pouvez-vous expliquer pourquoi ils ont pu être confondus avec une mauvaise catégorie?
Pour ce scénario, nous avons analysé les 8 textes incorrectement classés par l’algorithme des k plus proches voisins. Les 3 discours du PLQ incorrectement classés datent de 1992, 1993 et 1994. Les 5 discours du PQ incorrectement classés datent quant à eux de 1981, 1985, 1999, 2002 et 2003. Les dernières années de Robert Bourassa (PLQ) au pouvoir apparaissent comme une période de rupture par rapport aux politiques budgétaires habituelles de son parti. La même chose peut être dite, pour le Parti Québécois, des dernières années où Lucien Bouchard et Bernard Landry ont influencé la politique économique du Québec.
Type de données
- Texte
Discipline
- Science politique